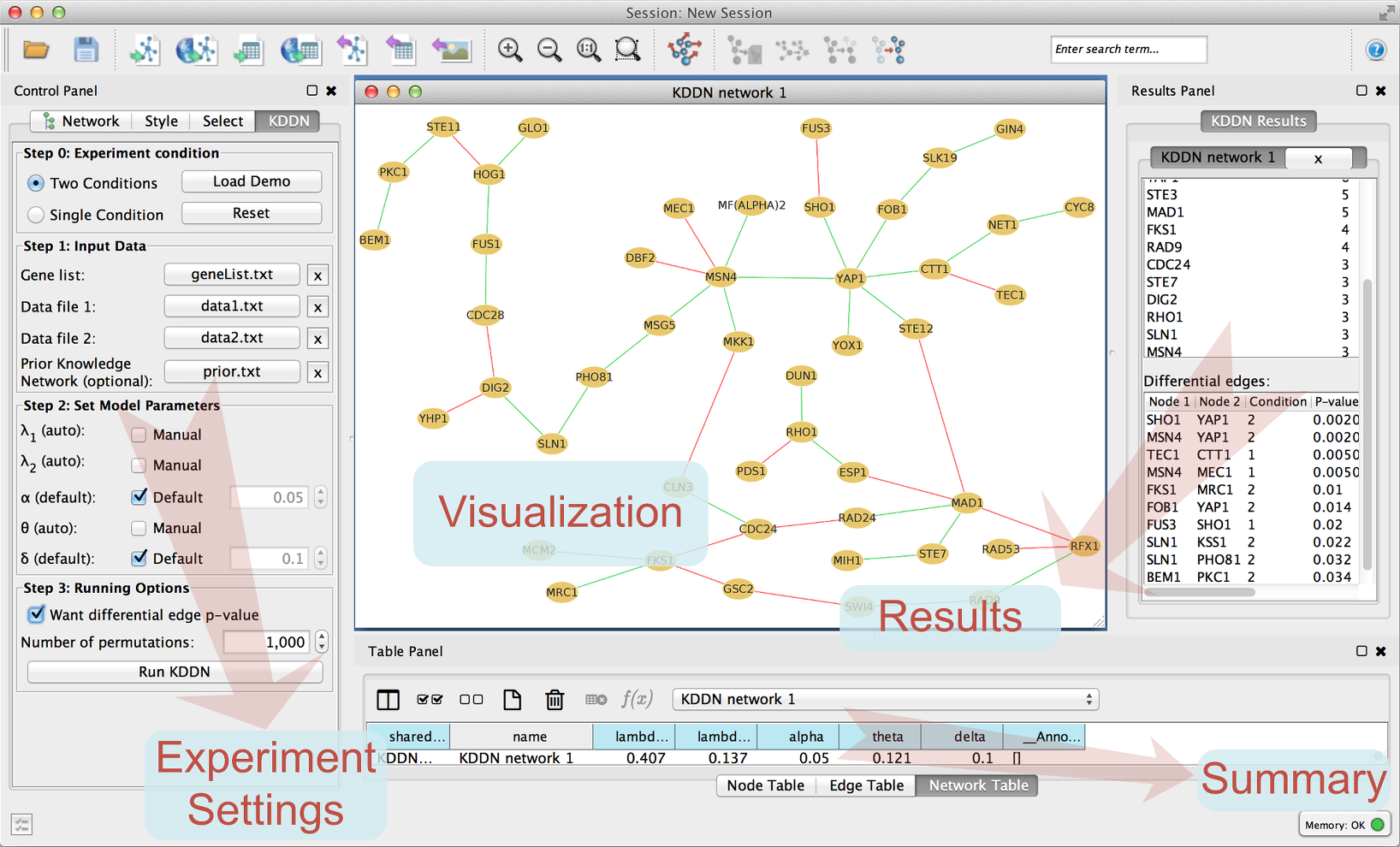
### KDDN
KDDN is a Cytoscape app to learn biological network topology and its changes using profiling data and domain knowledge. It takes input data and runs KDDN algorithm to construct the dependency network. When two conditions data are available, KDDN identifies the statistically significant condition-specific edges to provide insights into system dynamics.
A KDDN experiment can be performed following 4 steps:
1. Determine the experiment condition;
2. Provide input data;
3. Choose how you like the model parameters to be specified;
4. Configure running options.
***
### Step 0: Experiment Condition
KDDN can work with both single condition data and two conditions data. Users need to tell KDDN which learning is requested.
* Two Conditions
* Data for two conditions are provided. KDDN learns the differential edges between the two conditions. Red edges highlight connections exist only under condition 1 and green edges highlight connections exist only under condition 2.
* Single Condition
* Only data of condition 1 is used (or provided). KDDN learns a static network structure.
A demo dataset is provided for users to understand the usage and explore the settings.
* Load Demo
* Load the demo dataset including all required or optional files, and set all parameters to auto
mode. The dataset contains 18 genes. Users can cancel the demo dataset or replace with a new dataset (make sure the number of genes are the same). The demo dataset can be viewed at [https://github.com/tianye03/kddn-cytoscape/tree/master/src/main/resources/demo]
* Reset
* Reset KDDN to initial status.
***
### Step 1: Input Data
Profiling data and domain knowledge are specified in this step.
* Gene list
* A text file containing a list of nodes (genes, proteins) involved in the study. One node per line. No row/column names.
* Data file 1
* Profiling data (gene expression, protein expression, RNA-seq RPKM, etc.) of condition 1 in a text file with no row/column names. One node per row, corresponding to the same order in gene list file. Tab or comma delimited. Data should be properly normalized.
* Data file 2
* Profiling data (gene expression, protein expression, RNA-seq RPKM, etc.) of condition 2 in a text file with no row/column names. Not required or ignored when experiment condition is set to single condition.
* Prior knowledge network
* Prior knowledge of network topology in KGML format or a text file with no row or column names. A KGML xml file can be downloaded from the KEGG website ([http://www.genome.jp/kegg]). Text file input supports either general prior knowledge applied to both conditions or condition-specific prior knowledge. Text file input has no row or column names, and a row is a record of prior knowledge edge. If a row consists of two nodes names separated by tab or comma, it is identified as general prior knowledge. If a row consists of two nodes and a value of 1 or 2 separated by tab or comma, it is identified as a condition-specific prior knowledge that is only for condition 1 or 2. This file is optional. If provided, KDDN will use the knowledge in learning, otherwise it relies solely on data.
File choices can be canceled using button.
***
### Step 2: Model Parameters
Model parameters specifies all parameters in KDDN. Parameters can be set in auto mode or manual mode. Parameters are enabled or disabled according to specific settings.
* λ1
* It controls the overall density of the learned network. Larger λ1 leads to sparser networks. The default is in auto mode where it is calculated automatically from data. When manual mode is chosen, a spinner shows up to allow user to set a value.
* λ2
* It controls the density of identified differential edges. It is enabled only in two conditions experiments. Larger λ2 leads to fewer differential edges. The default is in auto mode where it is found automatically according to the value of α. When manual mode is chosen, a spinner shows up to allow user to set a value, and α setting is disabled.
* α
* The desired significance level of differential edges. It is used to find the corresponding value of λ2 automatically. It is enabled only in two conditions experiments and λ2 is set to auto. Check the default checkbox resets it to 0.05.
* θ
* The degree of prior knowledge incorporation. It is enabled only when the optional prior knowledge network file is provided. The default is in auto mode where it is found automatically according to the value of δ. When manual mode is chosen, a spinner shows up to allow user to set a value, and δ setting is disabled.
* δ
* The maximum tolerable deviation in the worst case scenario of prior knowledge incorporation. It is used to find the corresponding value of θ automatically. It is enabled only when the optional prior knowledge network file is provided and θ is set to auto. Check the default checkbox resets it to 0.1.
***
### Step 3: Running Options
When the input data meets the minimum requirements corresponding to experiment condition, run button is enabled to allow users to carry out experiments.
* Want differential edge p-value
* Enabled only in two conditions experiments. Check it will add more running time to perform permutation test to get edge-specific p-values for differential edges.
* Number of permutations
* The number of permutations used. It is enabled only in two conditions experiments and want differential edge p-value is checked.
After going through all steps, a final hit of run button will initiate the analysis. A progress bar informs users the progress of the three most time-consuming stages (if necessary according to settings): finding λ2, finding θ and calculate p-value.
***
### Results
After the calculation is completed, a network with an unique id is created and visualized, and summary information is provided in results panel and table panel.
Node names in the network view are the same with the ones in gene list file. In single condition experiment, static connections are displayed by gray edges. In two conditions experiment, differential network is displayed with red edges represent connections exist only under condition 1 and green edges represent connections exist only under condition 2.
There are four tables in the tabbed “Results” panel. Experiment parameters, Node connectivity degree, Differential edges (in two conditions experiments), and Network parameters.
* Experiment parameters
* A table summarized the parameters used in the experiment.
* Node connectivity degree
* A table lists the degree of all nodes and differential analysis results if applicable. In single condition experiments the degree is the number of static edges connected to the node. In two conditions experiments the degree is the number of differential edges connected to the node. In two conditions experiments, differential analysis including fold-change and t-test p-values are provided as additional columns. There is an export button in the table header that can export the table data in comma separated format.
* Differential edges
* A table lists all differential edges, if the experiment is two conditions. If p-values are calculated, a p-value column is added to the table. There is an export button in the table header that can export the table data in comma separated format.
* Network parameters
* A table contains all inferred network parameters (β). In single condition experiments there is one beta value for each edge. In two condition experiments beta values under both conditions are shown. There is an export button in the table header that can export the table data in comma separated format for other analysis of the inferred networks.
***
### Reference
Details regarding the methodology can be found at
Y. Tian, B. Zhang, E.P. Hoffman, R. Clarke, Z. Zhang, I.M. Shih, J. Xuan, D.M. Herrington and Y. Wang, “KDDN: An open-source Cytoscape app for constructing differential dependency networks with significant rewiring”, Bioinformatics, 2014.